Review ) SemGeo: Semantic Keywords for Cross-View Image Geo-Localization
https://ieeexplore.ieee.org/abstract/document/10094763
SemGeo: Semantic Keywords for Cross-View Image Geo-Localization
Image geo-localization refers to determining location of images using visual information. In cross-view image geo-localization, location of images are identified by matching them against a database of geo-tagged aerial imagery. The methods based on this ap
ieeexplore.ieee.org
abstract
cross view image geo localization이 low FoV(field of view)에서는 성능이 낮다는 것을 보완하기 위해서
color statistic 외에 semantic information을 사용함
이미지에서 semantic keywords를 고려하는 cross view image geo-localization framework인 SemGeo를 제안함
introduction
- scene의 semantic knowledge를 추출하고 인코딩함
- natural language에서 차용한 keyword representation을 고려하고 spatial arrangement를 블랜드해서 encoding을 제안함
- Open Street Map(OSM)의 geo data로부터 semantic tag를 활용하고, keyword source로 사용
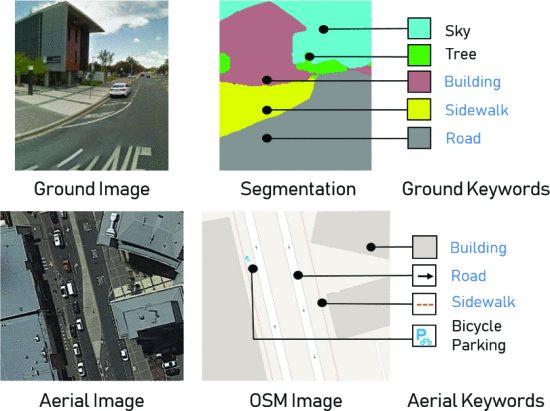
proposed method
1) problem statement and objective function
1-1) problem statement
cross-view image geo-localization의 목적은 동일한 region에 속하는 ground-view와 aerial-view에 해당하는 feature가 근접한 임베딩 공간과 pair에 대한 feature를 학습하는 것
1-2) objective function
soft-margin triplet loss
2) OSM as aerial keyword source
OSM의 street level geo-data로부터 시맨틱 테그를 reliable keyword source로 사용함
cross-view image geo-localization에 OSM의 keyword tag를 사용한 첫 번째 연구
3) semantic knowledge representation
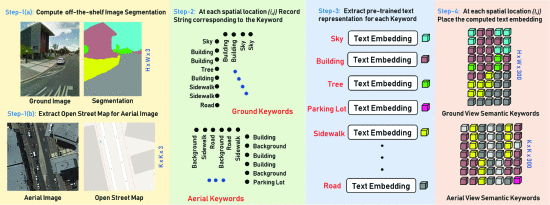
장면의 semantic knowledge을 인코딩하기 위해 새로운 인풋 표현체계를 제안함
natural language understanding에서 차용한 실제세계의 객체를 이해하는 것을 포함
1. semantic segmentaion/extracted OSM를 사용해서 scene에서 객체를 탐지함
2. 장면에서 감지된 객체에 해당하는 pre trained natural language text embedding of strings를 사용
3. their spatial arrangement와 함께 text embedding을 blend
4) model representation
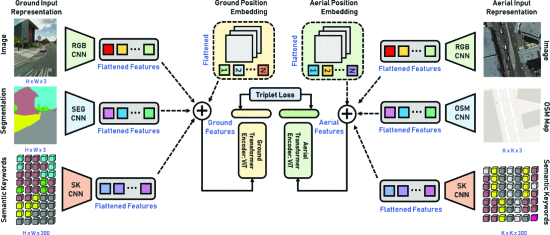
triplet loss function으로 학습된 샴 파이프라인을 사용
4-1) Ground and Aerial View Representation
목적 - 의미론적 지식을 인코딩하는 교차 뷰 feature를 학습함
joint representaion을 학습하기 위하여 transformer에 전달하기 전에 RGB, 세분화/OSM 및 제안된 시맨틱 키워드 표현의 개별 토큰화된 출력을 sum해서 수행
트랜스포머의 최종 인코더 클래스 토큰은 지상뷰 표현을 예측하기 위해 MLP로 전달됨
experiment
1) dataset - CVUSA, CVACT
2) Evaluation metric - recall@K
3) quantitative results - 낮은 FoV에 대해서도 잘 작동하였고, 하나의 데이터셋에서 훈련하고 다른 데이터셋에서 모델 일반화 능력 향상
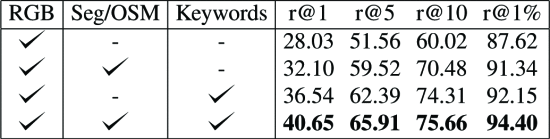
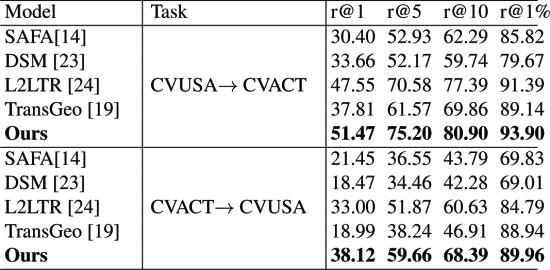
conclusion
natural language representation에서 지식을 가져와 의미론적 지식을 만들었고, transformer 기반 샴 프레임워크에 통합함