Learning Rate

모멘텀; momentum
- ML은 훈련집합으로 그래이디언트를 추정하므로 noise가 섞일 가능성이 큼
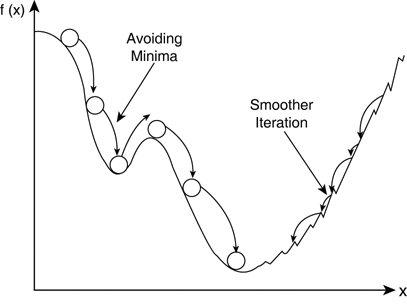
--> 그래디언트에 스무딩을 가하면 수렴 속도 개선이 가능함 --> momentum
- w가 이동하는 과정에 일종의 관성을 부여함
--> w를 업데이트할 때마다 이전 단계의 업데이트 방향을 반영함
- 기울기에 속도 개념이 추가됨
- 속도를 나타내는 벡터 v를 사용해서 그래디언트를 스무딩함
- 모멘텀을 적용하지 않는 경우 이동량이 너무 커 적절한 곳을 지나치는 overshooting 현상이 발생할 수 있음
- 주로 0.5, 0.9, 0.99를 사용함
- 현재는 이를 개선한 Nestrov momentum을 주로 사용
모멘텀의 장점
- SGD에 비해서 효율적인 학습이 가능 -> 수렴 속도 개선
- SGD의 문제인 local minima, plateau(평탄한 지점) 해결 가능
적응적 학습률 adaptive learning rate
- learning rate가 높으면 오버슈팅으로 진자운동, 너무 낮으면 해까지 너무 오랜 시간 소요
- 그래디언트는 벡터인데 학습률을 곱하면 k개의 매개변수가 모두 같은 크기의 학습률을 사용할 수 있음
- 적응적 학습률은 매개변수마다 상황에 따라 학습률을 조절해서 사용함
--> 바로 이전 그래디언트와 현재 그래디언트의 부호가 같으면 매개변수 값을 키움
RMSProp
- 오래된 그래디언트와 최근 그래디언트가 알고리즘 끝날때까지 같은 비중의 역할을 하면 충분히 수렴하지 못한채 학습률이 0에 가까워질 수 있음
- RMSProp는 오래된 그래디언트의 영향력을 지수적으로 줄임
- weighted moving average 기법을 사용함
- 0.9, 0.99, 0.999 등을 사용함
Adam ; Adaptive moment
- RMSProp에 모멘텀을 추가로 적용한 알고리즘