머신러닝
지도 방식에 따라
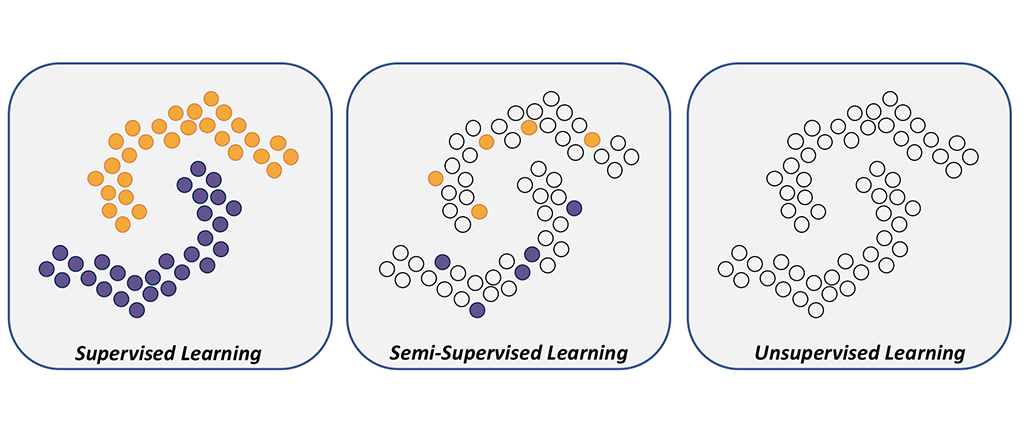
1. 지도학습
정답이 무엇인지 컴퓨터에 알려주고 학습시키는 방법
데이터가 입력(특징벡터)와 출력(목푯값) 쌍으로 주어짐
목적함수가 학습과정을 주도함
- 분류
k최근접이웃(KNN), 서포트 벡터 머신(SVM), 결정 트리, 로지스틱 회귀
- 회귀 : 출력이 연속된 실수로 주어짐
선형 회귀
-순위매기기ranking
: 주로 검색에서 사용됨. 관련 문서를 찾은 후 적합도에 따라 순위를 매겨 사용자에게 제공하는 목적
- 영상 변환
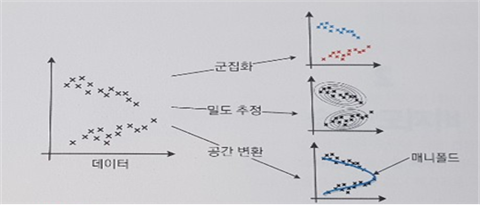
2. 비지도학습
정답을 알려주지 않고 특징이 비슷한 데이터를 클러스터링해서 예측하는 학습 방법
특징벡터만 주어짐
유사도 기반(데이터 간 거리 측정)으로 특징이 유사한 데이터끼리 클러스터링으로 묶어서 분류됨
- 군집(클러스터링)
: 특징 공간에서 가까이 있는 샘플을 같은 군집으로 모음
K-means clustering, 밀도기반 군집 분석
- 특징 공간의 변환
매니폴드 학습, LLE, IsoMap, t-SNE, 주성분 분석(PCA)
사전 지식 prior knowledge
명시적인 정보뿐만 아니라 세상의 일반적인 규칙으로부터 얻을 수 있는 암시적인 정보
* manifold hypothesis
데이터집합은 하나의 매니폴드 또는 여러 개의 매니폴드를 구성하며, 모든 샘플은 매니폴드와 가까운 곳에 존재함
* smoothness hypothesis
샘플은 어떤 요인에 의해 변화함
일반 과업
특정 응용과 무관하게 풀어야 하는 일반 과업
* 군집화 : 유사한, 특징 공간에서 가까이 있는 샘플을 모아 같은 그룹으로 묶는 일
* 밀도 추정 : 데이터로부터 확률분포를 추정하는 일 - 모수적 추정법/ 비모수적 추정법으로 분류
* 공간 변환 : 데이터가 정의된 원래 특징 공간을 저차원 공간 또는 고차원 공간으로 변환, 새로운 공간은 주어진 목적 달성에 더 유리해야 함
응용과 목적에 따라 다양한 공간 변환 알고리즘이 존재함
응용 과업
* 군집화 : 영상이 입력되면 각각의 화소를 RGB 세 가지 색상 요소와 화소 위치를 나타내는 두 요소를 결합한 5차원 특징 벡터로 표현한 다음 군집화 가능
--> https://sheepsurim.tistory.com/50
* 밀도 추정 : 부류별로 확률밀도 함수 추정할 수 있으면 베이즈 정리 적용해서 분류 과업 해결 가능
--> https://sheepsurim.tistory.com/51
* 공간 변환 : 데이터 가시화 목적으로 2차원 또는 3차원으로 축소하는 응용 과업이나 적절한 차원으로 축소해서 데이터 압축
3. 강화학습
자신의 행동에 대한 보상을 받으며 학습을 진행함
연속된 샘플의 열에 목푯값 하나만 주는 방식
샘플 열에 속한 각각의 샘플에 목푯값을 배분하는 알고리즘이 추가로 필요함
보상이 커지는 행동은 자주 하도록 하고, 줄어드는 행동은 덜 하도록 하여 학습을 진행함
마르코프 결정 과정(Markov Decision Process)
4. 준지도학습
데이터 수집의 부담 -> 목표값은 사람이 수행해야함(라벨링)
소량의 데이터에만 부류 정보를 부여 후 부류 정보가 있는 소량의 데이터와 부류 정보가 없는 대량의 데이터를 함께 활용하여 성능 향상을 모색함
다양한 기준에 따라
* 오프라인과 온라인
오프라인 : 데이터베이스 수집, 학습, 예측이라는 순차를 따름
온라인 : 추가적으로 발생한 데이터를 가지고 점증적으로 추가 학습하여 성능을 조금씩 개선하는 기계 학습 방식
* deterministic과 stochastic learning
deterministic : 같은 데이터베이스로 다시 학습하면 같은 예측기가 만들어짐. 초깃값이 난수
stochastic : 학습하는 중간에 난수를 사용함. 예측 과정에서도 난수를 사용함. 확률 분포에 따라 예측함
* discriminative model learning과 generative model learning
discriminative : 샘플의 부류를 예측함
generative : 발생할 확률을 명시적으로 계산해서 새로운 샘플을 생성함
딥러닝 모델 학습 과정
1. 데이터 준비
파이토치나 케라스에서 제공하는 데이터셋 사용. 이미 전처리 되어있음.
캐글과 같은 공개 데이터 사용
2. 모델(모형) 정의
은닉층 갯수가 많을수록 성능이 좋아지지만 과적합(훈련 데이터를 과하게 학습해서 오차는 감소하는데 새로운 데이터에서는 오차가 커짐)이 발생할 확률이 높음
3. 모델 컴파일
활성화함수, 손실함수, 옵티마이저를 선택
훈련 데이터가 연속형이면 MSE
훈련 데이터가 이진 형이면 크로스 엔트로피
4. 모델 훈련
한 번에 처리할 데이터 양을 지정
한번에 처리해야 할 데이터 양이 많아지면 학습 속도가 느려지고, 메모리 부족 문제를 야기할 수 있음.
전체 훈련 데이터셋에서 일정 묶음으로 나누어 처리할 수 있는 배치와 훈련 횟수인 에포크 선택이 중요함
값의 변화를 시각적으로 표현해서 눈으로 확인하면서 파라미터(모델 내부에서 결정되는 변수)와 하이퍼파라미터(튜닝, 최적화해야하는 변수, 사람들이 선험적 지식으로 설정하는 변수)에 대한 최적의 값을 찾음
배치가 끝날때마다 모델 가중치를 한 번씩 업데이트 시킴.
ex. 훈련 데이터셋 1000개에 대하여 배치 크기가 20이면 샘플 단위 20개마다 모델 가중치를 한 번씩 업데이트 시킴
에포크가 10이면 가중치를 50번 업데이트를 10번을 반복하기 때문에 총 500번 업데이트됨.
5. 모델 예측
검증 데이터셋을 생성한 모델에 적용해서 실제로 예측을 진행해보는 단계
딥러닝은 심층 신경망을 사용하고, 가중치 값을 업데이트 하기 위해 역전파가 중요함
역전파 계산 과정에는 미분(오차를 가중치로 미분)이 성능에 영향을 줌
-> 파이토치 같은 프레임워크는 역전파 알고리즘을 자동으로 구처리해줌
% 딥러닝 학습 알고리즘
지도 학습
합성곱 신경망(CNN)은 이미지 분류, 이미지 인식, 이미지 분할로 분류 가능함.
시계열 데이터 분류에 사용되는 것이 순환 신경망(RNN)
기울기 소실을 방지 하기 위해 게이트를 3개 추가한 것(망각, 입력, 출력)이 LSTM--> 최근 가장 많이 사용됨
비지도 학습
워드 임베딩: 단어를 벡터로 표현 -> 의미를 벡터화하는 워드투벡터, 글로브 사용
군집 : 아무 정보가 없는 상태에서 데이터 분류하는 방법, 머신러닝 군집과 다르지 않음. 신경망에서 군집 알고리즘 사용하기도 함
차원 축소 : PCA
전이 학습(transfer learning)
pre-trained 모델을 가지고 원하는 학습에 미세 조정 기법(fine tune)을 이용해서 학습하는 방법
사전에 학습이 완료된 모델이 필요함
사전 학습 모델
많은 데이터로 이미 학습이 되어 있는 모델
ex. VGG, MobileNet, 인셉션
'Pytorch' 카테고리의 다른 글
| torch.nn과 torch.nn.functional (0) | 2023.09.11 |
|---|---|
| ResNet Image Feature Extraction (0) | 2023.09.04 |
| 파이토치 모델 정의 (0) | 2022.04.30 |
| 파이토치 기초 문법 (0) | 2022.04.28 |
| 파이토치 기초 (0) | 2022.04.27 |